该函数的设计本质上是一个很难的问题。综述中给出了如下的设计提升方案:
* Rule-Based Simulation Policy * Contextual Monte Carlo Search * Fill
the Board * Learning a Simulation Policy * Using History Heuristics *
Evaluation Function * Simulation Balancing * Last Good Reply *
Patterns
defsearch(self, canonicalBoard): """ This function performs one iteration of MCTS. It is recursively called till a leaf node is found. The action chosen at each node is one that has the maximum upper confidence bound as in the paper. Once a leaf node is found, the neural network is called to return an initial policy P and a value v for the state. This value is propagated up the search path. In case the leaf node is a terminal state, the outcome is propagated up the search path. The values of Ns, Nsa, Qsa are updated. NOTE: the return values are the negative of the value of the current state. This is done since v is in [-1,1] and if v is the value of a state for the current player, then its value is -v for the other player. Returns: v: the negative of the value of the current canonicalBoard """
# 将状态转化为字符串的形式 s = self.game.stringRepresentation(canonicalBoard)
# 如果状态不在之前是否记录表中,则重新检测是否为终态。 if s notinself.Es: # 是终态返回 1 or -1(表示胜负结果),不是终态返回 0 self.Es[s] = self.game.getGameEnded(canonicalBoard, 1)
# 如果不在策略的记录表中,产生初始策略 if s notinself.Ps: # leaf node # 神经网络评估该状态价值 self.Ps[s], v = self.nnet.predict(canonicalBoard) # 产生所有合法移动 valids = self.game.getValidMoves(canonicalBoard, 1) # 遮盖不合法移动 self.Ps[s] = self.Ps[s] * valids # masking invalid moves sum_Ps_s = np.sum(self.Ps[s]) if sum_Ps_s > 0: self.Ps[s] /= sum_Ps_s # renormalize else: # if all valid moves were masked make all valid moves equally probable
# NB! All valid moves may be masked if either your NNet architecture is insufficient or you've get overfitting or something else. # If you have got dozens or hundreds of these messages you should pay attention to your NNet and/or training process. log.error("All valid moves were masked, doing a workaround.") self.Ps[s] = self.Ps[s] + valids self.Ps[s] /= np.sum(self.Ps[s])
# 温度相当于给予不同动作一个概率,如果temp=1则直接贪心选择 defgetActionProb(self, canonicalBoard, temp=1): """ This function performs numMCTSSims simulations of MCTS starting from canonicalBoard. Returns: probs: a policy vector where the probability of the ith action is proportional to Nsa[(s,a)]**(1./temp) """ # 进行多次模拟 for i inrange(self.args.numMCTSSims): self.search(canonicalBoard)
# 将状态编码为字符串 s = self.game.stringRepresentation(canonicalBoard)
# 遍历当前状态下,所有合法动作已经探索过的次数 counts = [self.Nsa[(s, a)] if (s, a) inself.Nsa else0for a inrange(self.game.getActionSize())]
# 温度非0,给予每个动作一个归一化的被选择几率值 counts = [x ** (1. / temp) for x in counts] counts_sum = float(sum(counts)) probs = [x / counts_sum for x in counts] return probs

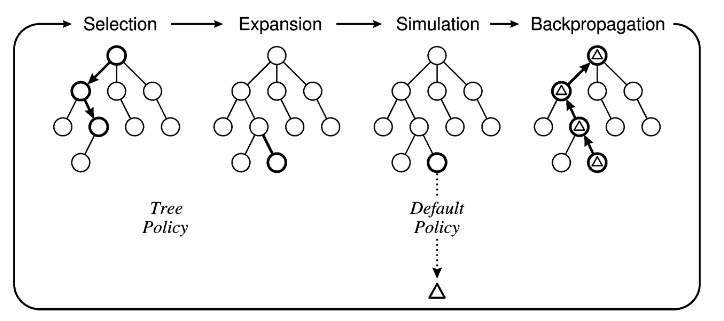


 以上式算法的伪代码。
以上式算法的伪代码。